2019 KAKAO BLIND RECRUITMENT 후보키 문제를 풀어보겠다.
1. 문제
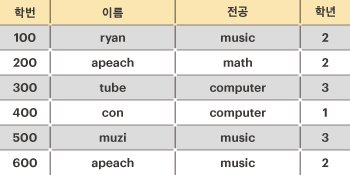
이런 테이블(2차원 배열)이 주어질 때, 후보키가 될 수 있는 개수를 구하는 문제다.
2. 링크
프로그래머스 2019 KAKAO BLIND - 후보키 문제 링크
3. 풀이
문제에서 유일성, 최소성 2가지 조건을 만족해야 한다.
최소 뽑을 수 있는 것부터 유일성을 검사한 후, 유일성 통과가 안될 시에 뽑는 개수를 한 개씩 늘려가면서 유일성을 만족하는 걸 찾는다.
- 유일성 만족 확인
- 각 컬럼의 문자를 공백을 사이에 두고 하나의 문자열로 통합 (공백을 둔 이유는 혹시나 서로 다른 컬럼인데 이어졌을 때, 같아질 때를 방지하기 위한 것,
ex) abs, sbs / ab, ssbs => abssbs 로 같아지게 된다.
- 이 문자들의 유일성 검사를 hashSet을 이용함.
- 행에 속하는 문자들 통합이 hashSet에 있을 경우, 유일성을 만족 못함, 만족할 경우 hashSet에 넣음
- 최소성 만족 확인(정답 코드의 경우)
- bit 마스킹을 이용해 만족하는지 확인
- (뽑은 컬럼 값의 bit 마스크 & 정답 후보에 있는 bit 마스크) = 정답 후보에 있는 bit 마스크 일 경우, 최소성 만족을 못함
여기서 (3, 2) 이런 식으로 (2, 3)의 순서만 바뀐 조합은 안 나오게 한다.
1) 오답
처음 코드에서는 42.9점으로 오답이 나왔었다. 이유는 다음과 같은 반례 때문이다.
반례
[["1", "2", "3"], ["2", "3", "1"], ["2", "3", "3"]]
정답: 2 => (0,2), (1,2)
return 3 => (0,1,2), (0,2), (1,2)
최소성을 보장 못한다.
이 코드의 경우 dfs 방식으로 뽑은 개수별로 순차적으로 확인하지를 않는다.
예를 들어, 컬럼 (1,3)의 조합이 유일성을 만족한다고 했을 때, 탐색을 다음과 같이 하게 된다.
(1) → (1,2) → (1,2,3) ⇒ 유일성 만족, 정답 개수++
→ (1,3) → 유일성 만족, 정답 개수++
이때 (1,2,3)은 (1,3)이 이미 후보키이기 때문에 최소성을 만족하지 못한다.
⇒ 개수를 순차적으로 뽑는 bfs 방법을 사용해야 한다.
import java.util.*;
class Solution {
int ans=0, row, col;
String[][] rel;
public int solution(String[][] relation) {
rel=relation;
row=relation.length;
col=relation[0].length;
proc(0,new ArrayList<>());
return ans;
}
//유일성을 못 맞출 경우, 컬럼 조합을 늘려간다.
public void proc(int cnt, ArrayList<Integer> combi){
// if(cnt>=col) return;
int start=combi.isEmpty()?0:combi.get(combi.size()-1)+1;
for(int j=start;j<col;j++){
boolean chk=true;
HashSet<String> hs=new HashSet<>();
for(int i=0;i<row;i++){
StringBuilder sb=new StringBuilder();
for(int k=0;k<cnt;k++){
sb.append(rel[i][combi.get(k)]+" ");
}
sb.append(rel[i][j]);
String result=new String(sb);
if(hs.contains(result)){
chk=false;
ArrayList<Integer> temp=new ArrayList(combi);
temp.add(j);
proc(cnt+1, temp);
break;
}
hs.add(result);
}
if(chk){
ans++;
}
}
}
}
2) 정답
bfs 방식으로 바꾸고, 비트마스킹 사용
유일성을 만족했을 시, 비트마스킹을 통해 부분 집합이 이미 유일성을 만족하지 않는지 확인한다.
예를 들어, 아까와 같은 예시로 컬럼 (1,3)의 조합이 유일성을 만족한다고 했을 때를 생각해본다.
지금 같은 bfs 방식일 경우, 다음과 같이 검사를 한다.
⭕: 유일성 만족, ❌: 유일성 불만족
1 ❌→ 2 ❌ → 3 ❌ → (1, 2) ❌ → (1, 3) ⭕ → (1, 4) ❌→ (2, 3) ❌ → (1, 2, 3) ⭕
유일성을 만족하는 조합은 (1, 3), (1, 2, 3), 이렇게 2가지다.
여기서 (1, 2, 3)은 이미 (1, 3)이 후보키이기 때문에 최소성이 만족하지 못한다. 따라서 부분 집합이 이미 후보키일 경우, 걸러줘야 한다.
비트마스킹으로 보면,
(1, 2, 3) ⇒ 0111
(1, 3) ⇒ 0101
& ⇒ 0101 == 0101
따라서 & 연산을 했을 때, 후보키랑 같은 게 나오면 최소성을 불만족하게 된다.
만약, (1, 4), (1, 2, 3) 이 후보키인게 있다고 하자. 그러면
(1, 2, 3) ⇒ 0111
(1, 4) ⇒ 1001
& ⇒ 0001 ≠ 1001
(1, 4)는 (1, 2, 3)의 부분 집합이 아닌걸로 정확하게 나온다.
class Solution {
int row, col;
String[][] rel;
public int solution(String[][] relation) {
rel=relation;
row=relation.length;
col=relation[0].length;
int ans=proc();
return ans;
}
//유일성을 못 맞출 경우, 컬럼 조합을 늘려간다.
public int proc(){
ArrayDeque<int[]> q=new ArrayDeque<>(); // 비트마스킹, 맨 뒤 idx
q.add(new int[]{0,-1});
ArrayList<Integer> ans=new ArrayList<>();
while(!q.isEmpty()){
int[] info=q.poll();
int start=info[1]+1;
for(int j=start;j<col;j++){
boolean chk=true;
HashSet<String> hs=new HashSet<>();
int bit=info[0]|1<<j;
for(int i=0;i<row;i++){
StringBuilder sb=new StringBuilder();
for(int k=0;k<8;k++){
if((info[0]&1<<k)!=0){
sb.append(rel[i][k]+" ");
}
}
sb.append(rel[i][j]);
String result=new String(sb);
if(hs.contains(result)){
chk=false;
q.add(new int[]{bit, j});
break;
}
hs.add(result);
}
if(chk){
boolean isHubo=true;
for(int hubo : ans){
if((hubo&bit)==hubo){
isHubo=false;
break;
}
}
if(isHubo) {
ans.add(bit);
}
}
}
}
return ans.size();
}
}
테스트 1 〉 통과 (2.70ms, 87.5MB)
테스트 2 〉 통과 (2.44ms, 86.2MB)
테스트 3 〉 통과 (2.19ms, 85.8MB)
테스트 4 〉 통과 (2.88ms, 91.1MB)
테스트 5 〉 통과 (2.62ms, 75.3MB)
테스트 6 〉 통과 (0.44ms, 82MB)
테스트 7 〉 통과 (0.40ms, 67.9MB)
테스트 8 〉 통과 (2.71ms, 75.9MB)
테스트 9 〉 통과 (4.11ms, 84.7MB)
테스트 10 〉 통과 (0.59ms, 87.5MB)
테스트 11 〉 통과 (3.46ms, 86.6MB)
테스트 12 〉 통과 (3.63ms, 75.8MB)
테스트 13 〉 통과 (3.78ms, 72.3MB)
테스트 14 〉 통과 (4.25ms, 83.8MB)
테스트 15 〉 통과 (2.14ms, 87.4MB)
테스트 16 〉 통과 (2.51ms, 74.8MB)
테스트 17 〉 통과 (3.15ms, 75.8MB)
테스트 18 〉 통과 (4.32ms, 77.7MB)
테스트 19 〉 통과 (3.38ms, 90.8MB)
테스트 20 〉 통과 (4.50ms, 75.6MB)
테스트 21 〉 통과 (4.58ms, 90.5MB)
테스트 22 〉 통과 (4.84ms, 93.6MB)
테스트 23 〉 통과 (2.25ms, 84.1MB)
테스트 24 〉 통과 (3.79ms, 85MB)
테스트 25 〉 통과 (4.65ms, 73.1MB)
테스트 26 〉 통과 (4.68ms, 87.5MB)
테스트 27 〉 통과 (2.99ms, 90.9MB)
테스트 28 〉 통과 (4.26ms, 84.9MB)
4. 시간 개선(문자열 체이닝)
StringBuilder 같은 클래스에서 append() 메서드를 연달아 이어서 호출하는 방식
1) 기존 코드 (임시 문자열 생성)
sb.append(rel[i][k] + " ");
rel[i][k] + " " 때문에, rel[i][k]와 " "을 합친 새로운 String 객체가 매번 만들어지고, 그다음에야 append()가 호출된다.
즉, 매번 불필요한 중간 문자열 객체가 생겨 성능 저하로 이어진다.
2) 문자열 체이닝 방식
sb.append(rel[i][k]).append(' ');
여기서는 먼저 rel[i][k]를 붙이고, 곧바로 ' '(공백 문자)를 붙인다.
그러면, 중간에 임시 String 객체가 전혀 안 생기고, StringBuilder 내부 버퍼에 바로 기록된다.
import java.util.*;
class Solution {
int row, col;
String[][] rel;
public int solution(String[][] relation) {
rel=relation;
row=relation.length;
col=relation[0].length;
int ans=proc();
return ans;
}
//유일성을 못 맞출 경우, 컬럼 조합을 늘려간다.
public int proc(){
ArrayDeque<int[]> q=new ArrayDeque<>(); // 비트마스킹, 맨 뒤 idx
q.add(new int[]{0,-1});
ArrayList<Integer> ans=new ArrayList<>();
while(!q.isEmpty()){
int[] info=q.poll();
int start=info[1]+1;
for(int j=start;j<col;j++){
boolean chk=true;
HashSet<String> hs=new HashSet<>();
int bit=info[0]|1<<j;
for(int i=0;i<row;i++){
StringBuilder sb=new StringBuilder();
for(int k=0;k<8;k++){
if((info[0]&1<<k)!=0){
sb.append(rel[i][k]).append(" "); // 체이닝 사용
}
}
sb.append(rel[i][j]);
String result=new String(sb);
if(hs.contains(result)){
chk=false;
q.add(new int[]{bit, j});
break;
}
hs.add(result);
}
if(chk){
boolean isHubo=true;
for(int hubo : ans){
if((hubo&bit)==hubo){
isHubo=false;
break;
}
}
if(isHubo) {
ans.add(bit);
}
}
}
}
return ans.size();
}
}
테스트 1 〉 통과 (0.13ms, 75.3MB)
테스트 2 〉 통과 (0.14ms, 85MB)
테스트 3 〉 통과 (0.15ms, 72.9MB)
테스트 4 〉 통과 (0.16ms, 84.7MB)
테스트 5 〉 통과 (0.16ms, 73.9MB)
테스트 6 〉 통과 (0.10ms, 74.5MB)
테스트 7 〉 통과 (0.09ms, 80.8MB)
테스트 8 〉 통과 (0.10ms, 89.7MB)
테스트 9 〉 통과 (0.17ms, 79.6MB)
테스트 10 〉 통과 (0.15ms, 88.9MB)
테스트 11 〉 통과 (0.29ms, 78MB)
테스트 12 〉 통과 (0.75ms, 79.6MB)
테스트 13 〉 통과 (0.46ms, 85.9MB)
테스트 14 〉 통과 (0.15ms, 90MB)
테스트 15 〉 통과 (0.10ms, 84.8MB)
테스트 16 〉 통과 (0.17ms, 76.4MB)
테스트 17 〉 통과 (0.18ms, 76.5MB)
테스트 18 〉 통과 (1.51ms, 87.9MB)
테스트 19 〉 통과 (1.37ms, 74.8MB)
테스트 20 〉 통과 (1.35ms, 70.5MB)
테스트 21 〉 통과 (2.55ms, 85.3MB)
테스트 22 〉 통과 (1.64ms, 85.7MB)
테스트 23 〉 통과 (0.15ms, 82MB)
테스트 24 〉 통과 (0.61ms, 91.7MB)
테스트 25 〉 통과 (1.98ms, 80.9MB)
테스트 26 〉 통과 (1.53ms, 83.2MB)
테스트 27 〉 통과 (0.80ms, 90.2MB)
테스트 28 〉 통과 (0.71ms, 78.5MB)
5. 참고
비트마스킹을 안쓰고 했을 때 코드도 남겨놓겠다.
비트마스킹 대신 *10, +를 사용했다.
예를 들어, 뽑는 컬럼이 1, 2, 3이면 123이 된다.
import java.util.*;
class Solution {
int row, col;
String[][] rel;
public int solution(String[][] relation) {
rel=relation;
row=relation.length;
col=relation[0].length;
int ans=proc();
return ans;
}
//유일성을 못 맞출 경우, 컬럼 조합을 늘려간다.
public int proc(){
ArrayDeque<int[]> q=new ArrayDeque<>(); // 뽑은 조합, 맨 뒤 idx
q.add(new int[]{0,-1});
ArrayList<Integer> ans=new ArrayList<>();
while(!q.isEmpty()){
int[] info=q.poll();
int start=info[1]+1;
for(int j=start;j<col;j++){
boolean chk=true;
HashSet<String> hs=new HashSet<>();
int bit=info[0]*10+(j+1);
for(int i=0;i<row;i++){
StringBuilder sb=new StringBuilder();
int num=info[0];
while(num>0){
int idx=num%10;
num/=10;
sb.append(rel[i][idx-1]+" ");
}
sb.append(rel[i][j]);
String result=new String(sb);
if(hs.contains(result)){
chk=false;
q.add(new int[]{bit, j});
break;
}
hs.add(result);
}
if(chk){
boolean isHubo=true;
for(int hubo : ans){
int num=hubo;
boolean isSub=true;
// 부분 집합이 이미 있는지 확인
while(num>0){
int ele=num%10;
num/=10;
boolean isExist=false;
int num2=bit;
while(num2>0){
int ele2=num2%10;
num2/=10;
if(ele==ele2){
isExist=true;
break;
}
}
if(!isExist){
isSub=false;
break;
}
}
if(isSub){
isHubo=false;
break;
}
}
if(isHubo) {
ans.add(bit);
}
}
}
}
return ans.size();
}
}
- 실행 시간
비트마스킹 썼을 때와 차이가 나지 않는다.
테스트 1 〉 통과 (1.99ms, 91.7MB)
테스트 2 〉 통과 (1.96ms, 72.7MB)
테스트 3 〉 통과 (2.10ms, 79.4MB)
테스트 4 〉 통과 (1.80ms, 93.7MB)
테스트 5 〉 통과 (2.08ms, 84.5MB)
테스트 6 〉 통과 (0.11ms, 82.4MB)
테스트 7 〉 통과 (0.09ms, 69.4MB)
테스트 8 〉 통과 (1.98ms, 76.1MB)
테스트 9 〉 통과 (2.25ms, 77.7MB)
테스트 10 〉 통과 (0.13ms, 82.8MB)
테스트 11 〉 통과 (2.23ms, 86.4MB)
테스트 12 〉 통과 (4.12ms, 87MB)
테스트 13 〉 통과 (2.70ms, 97.4MB)
테스트 14 〉 통과 (1.84ms, 77.1MB)
테스트 15 〉 통과 (1.79ms, 85.3MB)
테스트 16 〉 통과 (2.98ms, 84.3MB)
테스트 17 〉 통과 (2.07ms, 85.4MB)
테스트 18 〉 통과 (3.43ms, 89MB)
테스트 19 〉 통과 (3.08ms, 75.3MB)
테스트 20 〉 통과 (3.53ms, 82.9MB)
테스트 21 〉 통과 (4.11ms, 87.8MB)
테스트 22 〉 통과 (4.46ms, 92MB)
테스트 23 〉 통과 (1.93ms, 83.6MB)
테스트 24 〉 통과 (4.33ms, 83.5MB)
테스트 25 〉 통과 (5.04ms, 79.7MB)
테스트 26 〉 통과 (3.50ms, 86.9MB)
테스트 27 〉 통과 (2.63ms, 72.9MB)
테스트 28 〉 통과 (3.20ms, 85.6MB)





